
目次
育ちは C++ ですが、最近は主に C# を使用している A.O. です。
最近、社内で行われる勉強会に向けて C 言語(※1)のソースコードを作成していた際、思わぬ不具合に遭遇してしまったのでその不具合についてお話します。
※1:コンパイラは”gcc version 6.3.0 (MinGW.org GCC-6.3.0-1)”
まずは遭遇した不具合がどのようなものか、不具合を内包するソースコードと結果を見ながら説明します。(初歩的な C 言語の知識が必要になります)
まずは不具合を内包するソースコードを見てみましょう。
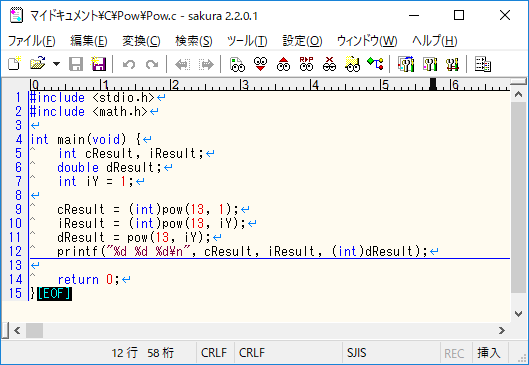
(図1:不具合を内包するソースコード)
これは math.h の pow 関数を用いて 13 の 1 乗を求めるだけのソースコードです。
サっと目を通しても不具合など無いように見えます。
このシンプルなこのソースコードのどこに不具合が存在するのでしょうか?
ソースコードを脳内ビルドして実行できた方は以下の結果をごらんください。
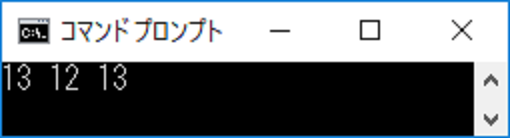
(図2:図1をビルドして実行した結果)
どうしてこうなったなんということでしょう!
普通に 13 の 1 乗を求めたはずですが 12 というよくわからない結果が出ています。
しかも 3 つの計算式の内 1 つだけで、その処理の差は殆どありません。
定数型でべき乗すると正しい値が出力されるにも関わらず、整数型でべき乗すると誤った値が出力されるのは「何故」でしょう?
一旦浮動小数点型に代入してから整数型に代入した結果と直接整数型に代入した結果が異なるのは「何故」でしょう?
次章では、この「何故」を解明していきたいと思います。
ここからは不具合の原因について説明します。
「自分で原因を見つけたいのだ!」という挑戦者はブラウザバックして、解決したらここへ戻ってきてください。
今回の不具合は 3 つの仕様(不具合ではない)から構成されています。
それもアセンブリと C 言語とコンパイラから 1 つずつ送り込まれた仕様です。
そして (int)pow(13, iY) が 12 になる原因はアセンブリと C 言語の仕様にあります。
まずはアセンブリの仕様から見てみましょう。
・アセンブリ(コンパイラかも?)の仕様
ここではアセンブリの仕様を説明し、整数型に代入した結果と直接整数型に代入した結果が「何故」異なるのかを説明します。
しかし C 言語の話からアセンブリの話になることを疑問思う方もいらっしゃると思います。
「何故」アセンブリの話をするのかというと C 言語はビルドする過程でアセンブリに変換される部分があり、今回の不具合はそこの仕様からひきおこされたものだからです。
「アセンブリは分からん」という方もいらっしゃるかと思いますが安心してください。
私も分からんアセンブリの処理にはほぼ触れずに不具合の原因だけ説明します。(私が何となくでしか分かっていない上にネット上で見聞きした情報が大半ですが)
gcc のコンパイラオプションにはビルド途中のアセンブリを生成するオプションがあるので、それを使って以下のソースコードのアセンブリを比較します。
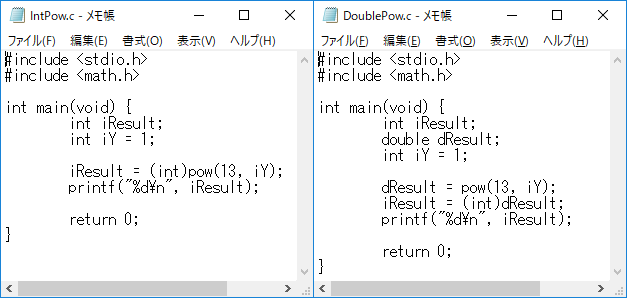
(図3:比較するソースコード)
図3のソースコードを簡単に説明すると、左が pow の結果を直接整数型に入れたもので、右がpow の結果を一旦浮動小数点型に代入してから整数型に代入したものです。
この 2 つをアセンブリに変換して差分を見ます。
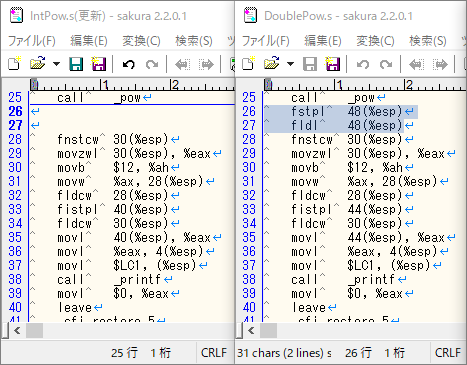
(図4:図3のソースコードをアセンブリに変換したもの)
図4を見てみると 26, 27 行目に差があることが分かります。
ここが何をしているかというと計算結果をメモリに格納し、それを引き出している処理だそうです。(※3)
「何故」ここで差が出るのかといいますと、計算結果とメモリの bit 数の違い(※4)により丸め誤差が発生しているからだそうです。
後述の C 言語の仕様で説明しますが pow の計算結果は 12.999… のような指数(≒小数部分)を持った浮動小数点型となっており、これが丸められることにより 12.999… と 13 という値の差が生まれ、キャストされることで 12 と 13 になってしまうようです。
※3:ここからの内容は検索して得た情報なので真偽は不明ですが多分正しいはず
(アセンブリは分からなかったよ・・・)
※4:情報のソースは同上ですが、最近メジャーな機械は計算に 80 bit 使用し、メモリに保持する際は 64 bit 使うらしいです。(そうなっている理由は全然わからん)
・C 言語(math.h の pow 関数)の仕様
前のアセンブリの仕様で指数を持つ浮動小数点型の値は変数に直接代入する場合と別の変数を経由する場合で結果が異なる可能性があることを説明しました。
ここでは pow 関数の結果が「何故」指数を持つ浮動小数点型になってしまったかを説明します。
まず pow 関数を簡単に説明します。
プロトタイプ宣言:double pow(double x, double y);
概要 :べき乗を行い、結果を返す
引数x :底
引数y :指数
戻り値 :xのy乗
見ての通り引数・戻り値の全てが浮動小数点型の関数です。
浮動小数点型 = 指数を持つ浮動小数点型ではないことに注意してください。
通常、指数を持たない浮動小数点型は指数を持たない正の浮動小数点型でべき乗しても、小数部がないため指数を持つことはありません。
それを踏まえると今回の pow 関数の結果は指数を持たない浮動小数点型になるはずです。
それが指数を持ってしまうのは powの内部で log を使用している(※5)ためです。
pow(x, y) は exp(log(x)*y) で計算することができるので math.h はその方法を用いている(※6)ようです。
しかし log(x) を使うと、小数部が発生してしまい指数を持ってしまいます。
これが pow 関数の結果が指数を持つ浮動小数点型になってしまう原因です。
※5:検索して得た情報なので真偽は不明です(それでいいのか)
※6:ソースは同上ですが、計算量が減るなどの恩恵があるらしいです
ここまでで (int)pow(13, iY) が 12 になってしまう理由がわかりました。
しかしそうなると (int)pow(13, 1) が 13 になる理由が分かりません。
(int)pow(13, iY) と (int)pow(13, 1) で「何故」結果が変わるのか、ここは次のコンパイラの仕様で説明したいと思います。
・コンパイラの仕様
前の C 言語の仕様で (int)pow(13, iY) が 12 になる理由を説明しました。
ここでは (int)pow(13, 1) が 13 に「何故」なるのかを説明します。
今回も処理そのものを比較しなければならないので、アセンブリの仕様に引き続きソースコードをアセンブリレベルで比較したいと思います。
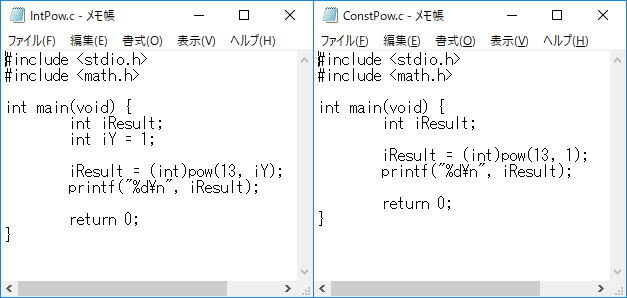
(図5:比較するソースコード)
図5のソースコードを簡単に説明すると、左が pow の引数に整数型を使用したもので、右がpow の引数に定数をそのまま使用したものです。
この 2 つをアセンブリに変換して差分を見ます。
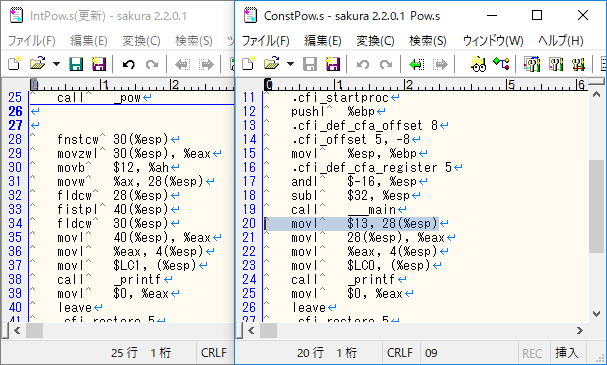
(図6:図5のソースコードをアセンブリに変換したもの)
図6を見てみると処理がまるで違うことが分かります。
これでは図4と異なり単純な比較はできそうにありません。
しかし、アセンブリを読めない私でも何となく分かることがあります。
左の35 ~ 38 行目と右の 21 ~ 24 行目はほぼ同じで、おそらく printf 関数を使用するために、値をメモリに設定しているような気がします。
そして、右の 21 行目で使用している値は、右のソースコードの 20 行目で 13 を代入しているような気がします。
端的に言ってしまうと pow 関数を使用していないのです。(大体推測ですが!!)
ここから推測交じりの結論になります。
変数を使わない pow 関数はアセンブリの段階で結果に変換されている。
これはビルド中にコンパイラが気を利かせて勝手に変換しているもので、アセンブリに変換した場合の結果とそれが異なるために 13 と 12 という差異が生まれる。
これで全ての「何故」を(多分!)解明することができました。
次章では、今回の不具合を改修する方法について考えていきます。
前章で挙げた不具合の原因を踏まえ、修正案を挙げてみます。
- pow 関数の結果を四捨五入する
- 整数型用の pow 関数を自作して呼び出す
前者は round 関数を用いる、または 0.5 を追加するという方法があります。
後者は整数型限定で誤差が無い関数を自作するものです。
取り合えず前者の方法で round 関数を用いるよう修正してみました。
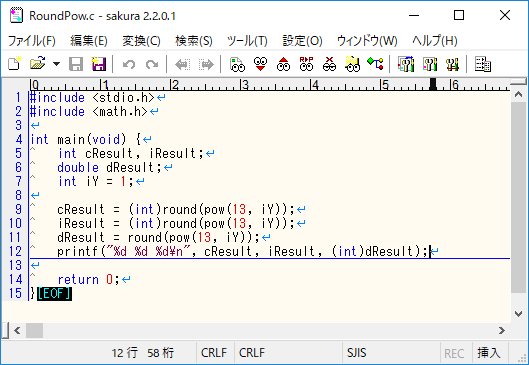
(図7:力技で修正したソースコード)
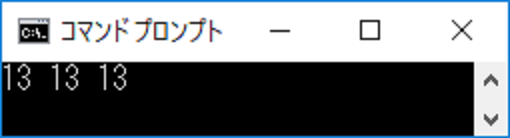
(図8:図7をビルドして実行した結果)
やりました、さすがに気分が高揚します。
(不具合との闘いを振り返りつつ不具合の無いソースコードを眺めて)
長くなってしまいましたが、遭遇した不具合の説明と修正案の提示は以上となります。
今回は普段 C 言語を使っていないがゆえに思わぬ不具合に遭遇してしまいましたが、得られるものも多く(業務と関係なかったので)良いタイミングで遭遇したと思います。
この不具合が業務などで出てしまい、今回記載した仕様を把握している開発者がいなかった場合、調査や報告などで多くの時間を浪費してしまうことでしょう。
そういった悲しい現象が発生しないよう、最近の言語はこういった暗黙のルールというべき仕様が減っており、新規参入者でも安心かつ楽に開発できるよう改善されています。
業務をスムーズに進めるならば、こういった言語の採用や学習は必要不可欠なのかもしれません。
もちろん機械語に近いが故の C 言語の速さも非常に魅力的なもので、現在も必要とされている場面があります。
昔の言語から得られる知識は、最近の言語を使用する上でも大きな武器になるはずです。
結局は環境や要件に合わせて使う言語を変えるスキルが私たちには要求されているのだと思います。
最後に、各種機械が高性能になっている昨今の情勢を踏まえ、
今回の不具合と戦った感想を記載して結びとさせていただきます。
「もう C 言語で書くなんて、言わないよ多分ね」